6月23日至27日,第61届设计自动化会议(DAC 2024)在美国旧金山召开。在本次大会上,来自电子设计自动化(EDA)与集成电路领域的高校、公司及研究机构群英荟萃,分享了EDA技术的最新发展和广泛应用,讨论了本领域进一步发展的前景和方向。北京大学多位教师代表,李萌、马宇飞、王宗巍等也担任了DAC的程序委员会(TPC)成员。燕博南研究员获得了SIGDA Outstanding New Faculty Award。集成电路学院的二十余位师生现场参加了本次大会,进行了汇报与交流。

燕博南研究员获得2024年SIGDA Outstanding New Faculty Award
在本次大会上,北京大学集成电路学院/集成电路高精尖创新中心共有12篇论文入选,研究成果覆盖了芯片设计、综合技术、体系架构、存算一体、设计自动化、软硬件协同等领域。相关介绍如下:
1. 跨阶段芯片功耗分析
随着集成电路的不断发展与芯片内集成晶体管数量的不断上升,芯片功耗问题已越来越成为制约芯片发展的重要因素。为了缓解功耗预算的紧张问题,设计阶段功耗优化已愈发重要。而为了促进更准确的功耗优化,芯片功耗分析是其中重要的一步。准确的功耗分析可以让设计者达到更理想的优化目标,并能更有信心地继续后续的流程。在不同阶段的芯片功耗分析当中,设计早期阶段的功耗分析尤为重要。在此前的工作中,只有商业工具覆盖了布局后功耗分析。但是商用工具没有考虑跨阶段必须要考虑的时钟树功耗、优化导致的电路网表变更带来的功耗差异,因此在分析上存在一定的精度不足问题。而电路网表变化又给数据驱动的机器学习方式带来很大困难。在此项工作当中,团队使用三阶段的训练方式。前两阶段为预训练,分别学习非时钟树功耗与时钟树功耗,而第三阶段采用校准的训练方式,对前两个阶段所获得的结果进行微调,从而进一步提升精度。前两阶段采用图神经网络对细粒度电路拓扑信息进行表征,而第三阶段进一步利用卷积神经网络对版图几何信息进行表征。两种模型的共同使用提升了模型的刻画能力并提升了整体预测的性能。在总运行时间对比商用工具缩短的前提下,实现了总功耗预测误差从9.6%到2.0%的提升。该工作以《PowPrediCT: Cross-Stage Power Prediction with Circuit-Transformation-Aware Learning》为题发表(本科生杜宇凡、博士生郭资政为共同第一作者,林亦波研究员为通讯作者)。

2. 系统级顶层布线
随着现代片上系统(SoC)规模的不断增长,多实例化分块技术因其可以有效降低不同部分的耦合度,显著降低了芯片开发的时间和人力成本。然而,不同分块之间关键连接的顶层布线带来了新的挑战。由于多实例化分块内部的路径会在其他相同模板的分块中复制,因此可能会产生布线资源的拥塞与浪费,甚至造成短路。针对这一难题,林亦波研究员团队提出了基于组搜索的带布线拓扑哈希的布线方法。该方法通过在双层稀疏格点图上的组搜索,能够鲁棒地解决由于布线路径复制导致地短路问题。同时,该方法通过对线网拓扑哈希的方式,有效减少了布线时间和线长。结果表明,与EDA菁英挑战赛赛题的获奖者相比,该算法能够在保持鲁棒性的同时,减少12%,32%,10%的总线长。该工作以《Top-Level Routing for Multiply-Instantiated Blocks with Topology Hashing》为题发表(博士生王嘉睿为第一作者,林亦波研究员为通讯作者)。
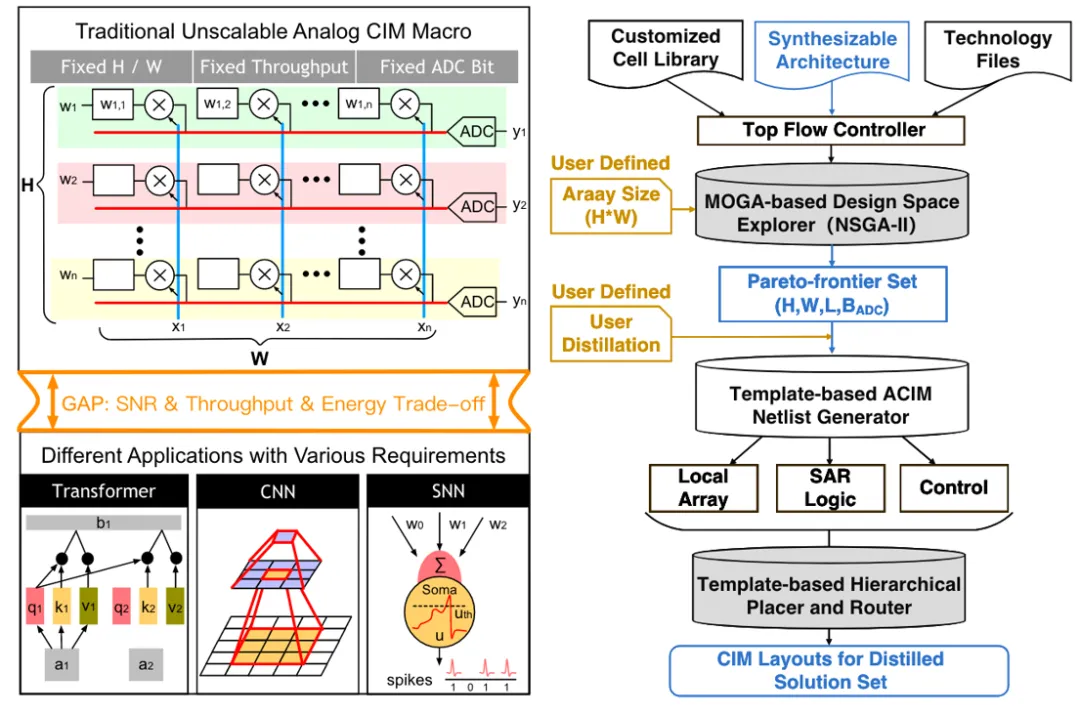
3. 可综合模拟存内计算
模拟存内计算(ACIM)是一种新兴架构,可用于执行高效的人工智能边缘计算。然而,目前的 ACIM 设计通常具有不可扩展的拓扑结构,并且仍然严重依赖人工操作。这些弊端限制了 ACIM 的应用场景,并延迟了设计者的设计时间。针对该问题,林亦波研究员-王润声教授团队提出了一种基于可合成架构的端到端自动化 ACIM(EasyACIM)。在给定阵列尺寸和定制单元库的情况下,EasyACIM 可以端到端自动生成具有各种设计规范的 ACIM 布局。利用基于多目标遗传算法(MOGA)的设计空间探索器,EasyACIM 可以基于所提出的可合成架构获得高质量的 ACIM 解决方案,从而满足各种应用场景的需求。与最先进的(SOTA)ACIM 相比,EasyACIM 提供的 ACIM 解决方案具有广阔的设计空间和极具竞争力的性能。该工作以《EasyACIM: An End-to-End Automated Analog CIM with Synthesizable Architecture and Agile Design Space Exploration》为题发表(博士生张昊懿为第一作者,林亦波研究员为通讯作者)。
4. 小型设备DNN内存优化
在微控制器等小型设备上部署深度神经网络(DNN,Deep Neural Network)来支持边缘智能应用的趋势正在不断增长。然而,在这类设备上部署DNN面临着重大挑战,因为DNN庞大的内存需求与小型设备严格的内存限制之间存在矛盾。一些先前的工作为了节省内存而承受了较大的延迟开销,并且仅针对简单的卷积神经网络;部分工作对复杂DNN进行粗粒度调度来减少峰值内存占用,但减少量有限。针对这一问题,梁云教授团队提出了一种名为MoteNN的方法,它通过在DNN上进行算子切分以实现细粒度调度,从而大幅降低峰值内存使用量,同时几乎不增加延迟开销。该方法提出了一种名为轴连接图(ACG,Axis Connecting Graph)的图数据结构,以高效地在图级别进行算子划分。该方法进一步提出了一种搜索算法,根据内存占用瓶颈来指导图划分和调度过程。实验结果表明,与最前沿的技术相比,该方法能够在小型设备上减少高达80%的峰值内存占用量,且几乎没有额外的延迟开销。该工作以《MoteNN: Memory Optimization via Fine-grained Scheduling for Deep Neural Networks on Tiny Devices》为题发表(博士生陈仁泽为第一作者,梁云教授为通讯作者)。
5. 存算一体的多尺度Transformer加速器
近年来,具有多头注意力(MHA)机制的 Transformer 模型在计算机视觉任务中展现出了良好的表现。然而,视觉Transformer(ViT) 缺乏归纳偏置,导致大量的计算和存储需求,使其难以在资源受限的边缘设备上部署。为此,涌现出了一批具有混合网络结构的多尺度ViT模型,以充分结合Transformer 与卷积神经网络(CNN)两者的优势。然而,现有的领域专用架构侧重于单独对卷积或 MHA 进行优化,且无法支持多尺度结构下灵活多变的层尺寸,缺乏灵活性与通用性。针对以上问题,黄如院士-叶乐教授、马宇飞研究员团队提出了一种存算一体(IMC)的AI加速器,通过引入流水线重排,有效加速具有混合卷积-MHA拓扑的多尺度ViT模型。SRAM 数字 IMC 宏被用于缓解内存访问瓶颈,同时避免模拟非理想性。此外,该工作中研究了可重构处理引擎和互连,以实现不同尺度下卷积和 MHA 的自适应映射。实验结果表明,相比基准设计,在典型的ViT工作负载下,所提出的架构可降低44.1%~55.9%的能量-延迟积(Energy-Delay-Product,EDP)。该工作以《An In-Memory Computing Accelerator with Reconfigurable Dataflow for Multi-Scale Vision Transformer with Hybrid Topology》为题发表(博士生陈至远为第一作者,人工智能研究院马宇飞研究员为通讯作者)。

文章第一作者陈至远现场报告
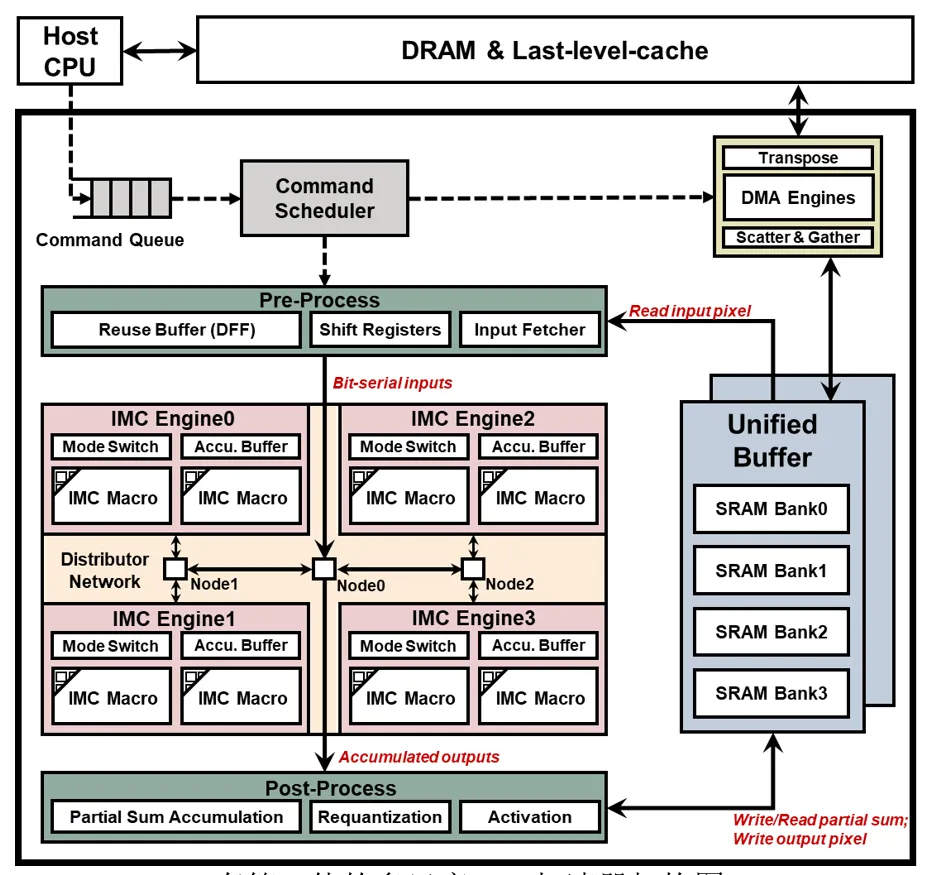
存算一体的多尺度ViT加速器架构图
6. 支持边缘学习的混合加速芯片架构
随着人工智能(AI)技术的不断发展,对于边缘端AI芯片的需求,如物联网(IoT)芯片,也在迅速增长。这对于资源有限的边缘端芯片来说无疑是一项巨大的挑战。特别是,设计一款既能支持推理又能支持训练的边缘端AI芯片是一项极具挑战性的任务。这需要我们在计算能力、能效比、内存带宽和存储容量等多个方面进行精细的优化和平衡。同时,我们还需要考虑到芯片的体积和成本,以满足边缘设备的实际需求和应用场景。针对上述问题,黄如院士-叶乐教授、贾天宇研究员团队提出了一种名为SPARK的高效混合加速架构,该架构能在训练TinyML网络时实时捕捉稀疏信息,并实现动态调度功能。除了独立的总线外挂加速器外,还在CPU流水线中实现了一个与流水线紧耦合的加速单元,以支持同时的前向和反向传播。为了更好地利用稀疏性并提高硬件利用率,该工作实现了一个能够实时捕捉稀疏信息的调度器,用以在两个加速单元之间调度工作负载。该工作使用台积电22纳米工艺实现了SPARK,并评估了不同的TinyML任务。SPARK在性能上比商用的边缘端设备高出9.4倍,效率高出446.0倍。该工作以《SPARK: An Efficient Hybrid Acceleration Architecture with Run-time Sparsity-Aware Scheduling for TinyML Learning》为题发表(本科生李明轩为第一作者,贾天宇研究员为通讯作者)。

7. 异构多档的存算一体Diffusion加速SoC芯片架构
随着AI内容生成算法的不断发展,Diffusion扩散模型在图像生成领域表现出卓越能力。然而,此类模型在硬件部署上面临巨大挑战,主要来源于其重复多轮的去噪过程、模型不同层次对计算和存储资源需求的不一致性,以及庞大的参数规模。针对上述问题,黄如院士-叶乐教授、贾天宇研究员团队利用存内计算(CIM)硬件高效执行计算任务,并提出了异构多档存算比方案,通过细粒度优化硬件时间和空间利用率,满足模型结构中割裂的计算和存储需求,提升存内计算集群的整体性能。此外,为满足应用的高性能需求,本工作还探索了芯粒扩展方案。采用2.5D集成技术,并结合针对存内计算硬件特性的工作负载平衡策略,优化了中间数据生成和传输调度,缓解了数据传输压力。在性能评估方面,我们使用内建的设计空间探索(DSE)框架和性能评估器,快速迭代出最优的多档异构设计方案。结果显示,异构多档存算设计相比传统同构方案显著提高了扩散模型任务部署中的硬件利用率。基于设计空间探索框架产生的芯片原型AIG-CIM集群,相比于RTX 3090 GPU,实现了两个数量级的吞吐量和能效提升。该工作以《AIG-CIM: A Scalable Chiplet Module with Tri-Gear Heterogeneous Compute-in-Memory for Diffusion Acceleration》为题发表(博士生景亦奇第一作者,贾天宇研究员和叶乐教授为通讯作者)。

8.大语言模型量化推理加速
在大语言模型(LLMs)中,会出现极少数具有异常高幅度的激活值,这些异常值对模型的准确性具有关键影响,为大语言模型低位宽量化推理带来了挑战。研究者们提出了多种混合精度量化技术来处理这些激活异常值,这些方法采用值级别的异常值粒度,面临在模型准确性与硬件效率之间实现平衡的挑战。针对这一难题,北大孙广宇和上交张宸团队提出了一种针对LLMs异常值感知的软硬件协同量化设计策略(Oltron)。Oltron利用了一个关键观察结果:LLMs的激活异常值并非完全随机分布,而是倾向于在特定通道中聚集。通过在较粗粒度上处理异常值,Oltron可以在保持模型准确性的同时,实现低量化位宽和高效硬件设计。针对层内/层间异常值通道的不规则分布问题,Oltron提出的软硬件协同量化方案能够自适应不同的异常值比例,该方案包括:自适应量化算法,能够识别不同层的最优异常值比率;基于分块的异常值均衡编码(TOBE)及相应的数据流优化器,可合理安排混合精度张量的复杂计算和内存访问;可重配置硬件架构,可在不同异常值比例下实现高效推理。Oltron在性能上超越了最先进的异常值感知加速器设计OliVe,实现了1.9倍的性能提升和1.6倍的能效提升,同时实现了较高的模型准确性。该工作以《Oltron: Software-Hardware Co-design for Outlier-Aware Quantization of LLMs with Inter-/Intra-Layer Adaptation》为题发表(北京大学博士生薛晨皓为第一作者,上海交通大学张宸助理教授和北京大学孙广宇副教授为通讯作者)。

9. 三维结构重建推理加速
体积成像(带有内部结构的三维模型)被广泛应用于多个领域,例如医学诊断和考古学,特别是在COVID-19大流行期间,对肺部CT的需求极大增加。然而,通过重建物体的内部结构来生成三维模型非常耗时。三维重建算法的数据局部性差、同步过程复杂,限制了基于领域专用电路(ASIC)加速方案的发展。针对这一难题,孙广宇副教授团队提出了一个使用软硬件协同设计的全面解决方案。该方法提供了一个统一的编程模型,以涵盖各种三维重建任务。基于此编程模型,该方法重新设计了重建算法的数据流,以改善数据局部性;通过仔细分析数据依赖关系,去除了不必要的同步。此外,该方法提出了一种新颖的近存储加速架构(Waffle),以进一步提高三维重建性能。实验结果显示,Waffle在单个封装中相比于10个GPU组成的集群,可以实现3.51~3.96倍的速度提升和9.35~10.97倍的能效提高。该工作以《A Software-Hardware Co-design Solution for 3D Inner Structure Reconstruction》为题发表(博士生李星辰为第一作者,孙广宇副教授为通讯作者)。
10. 大语言模型隐私计算
近年来,大语言模型兴起并被广泛应用于日常生活中,这些应用可能涉及数据的隐私信息。为了解决隐私问题,同态加密结合两方安全计算技术(HE+MPC)作为一种有前景的解决方案但代价是用户和模型提供方之间高额的通信量。尽管已有大量的工作尝试降低通信开销,我们发现大模型隐私推理中的词嵌入查找的优化被忽略了,而且实验表明这一过程的通信量和延迟与一层transformer层相当。基于此,团队提出了FastQuery框架,通过网络协议协同优化来降低词嵌入查找过程的通信量。在模型层面,FastQuery提出了通信感知的词嵌入表量化,通过逐通道细粒度的量化保证模型能力的同时显著降低明密文的位宽,进而降低通信开销。在协议层面,FastQuery提出了累加位宽减少以及将多个低比特元素排布进一个高比特元素中的协议优化,完全利用明文空间并降低通信开销。我们在LLAMA-7B和LLAMA-13B模型中验证了FastQuery的有效性。在模型准确率上,相比于ZeroQuant,FastQuery用更低的位宽取得了相当的PPL指标。与先前最先进的HE+MPC的框架相比,FastQuery取得了20-76倍的通信量降低,带来了1.3到4.3倍的延迟降低。该工作以《FastQuery: Communication-efficient Embedding Table Query for Private LLM Inference》为题发表(博士生林辰启、许天识、杨泽斌为共同第一作者,人工智能研究院李萌研究员为通讯作者)。

11. 模拟集成电路尺寸设计自动化
尺寸设计是模拟集成电路设计流程中的重要一环,也是对电路性能进行折中的关键途径。由于模拟信号对于PVT变化具有高敏感性,需要将PVT变化对电路的影响纳入尺寸自动设计流程。然而,目前的高PVT鲁棒性的尺寸自动设计工具存在优化成功率低、局部PVT角过拟合等问题,限制了尺寸设计工具的采样效率。对此,王源教授-唐希源研究员团队探索了先进AI算法在EDA领域的应用(AI for EDA),并研发了一款高PVT鲁棒性模拟集成电路尺寸自动工具PVTSizing。该工具搭建了一种基于贝叶斯优化和多任务强化学习的尺寸设计框架,采用了嵌入迭代环路内的 PVT角剪枝方式,并提出了一种基于Critic网络的尺寸剪枝算法,提高了尺寸设计工具的设计成功率和采样效率。在四种常用电路测试样例中,相较于先前的学术界和产业界的尺寸自动设计工具,PVTSizing可实现1.9~8.8倍的采样效率和1.6~9.8倍的时间效率。该工作以《PVTSizing: A TuRBO-RL-Based Batch-Sampling Optimization Framework for PVT-Robust Analog Circuit Synthesis》为题发表(博士生孔子琛为第一作者,人工智能研究院唐希源研究员和集成电路学院王源教授为通讯作者)。
12. 高效编码和搜索的CAM存内搜索架构
内容寻址存储器(CAM)由于其高度并行的存内搜索能力,已经在数据密集型的搜索应用中引起了广泛关注。大多数前沿研究致力于通过利用各种新兴的非易失性存储器技术来降低CAM的硬件成本。然而,现有的CAM设计仍主要沿用传统的编码方案,每个条目(entry)和查询(query)的每一位分别需要两个互补的存储节点和搜索信号,且需要分离的预充和评估阶段进行向量搜索,限制了CAM在面积和能效方面的进一步优化。针对上述问题,黄如院士-黄芊芊研究员团队通过对CAM编码方式和搜索方式的协同优化,提出了一种紧凑且高效的CAM架构。提出的新型组合编码方式通过将多个存储节点作为一组,通过排列和组合编码多位entry/query状态,显著提高了编码效率,将编码效率从传统编码方式的50%提高到接近100%,从而极大降低了CAM的硬件成本。此外,提出了一种新型自终止搜索方案,在预充匹配线阶段的同时检测匹配条件,一旦检测到匹配则终止预充过程,从而进一步减少搜索延迟和能量消耗。进一步基于铁电场效应晶体管对所提出的CAM架构进行了评估,结果表明在数据搜索任务中,面积-能量-延迟积相比传统CMOS CAM降低了1182倍,展示了其在高效存内搜索加速器领域的巨大潜力。该工作以《Compact and Efficient CAM Architecture through Combinatorial Encoding and Self-Terminating Searching for In-Memory-Searching Accelerator》为题发表(博士生徐伟凯为第一作者,黄如院士和黄芊芊研究员为通讯作者)。





